リソースを整理して公開することにしました。一方面是大体の思路を共有し、もう一方面は記念の意味も兼ねています。取り組んだのは2020年電気競技F問題:簡易非接触温度測定と身份認識装置

2020年電気競技F問題
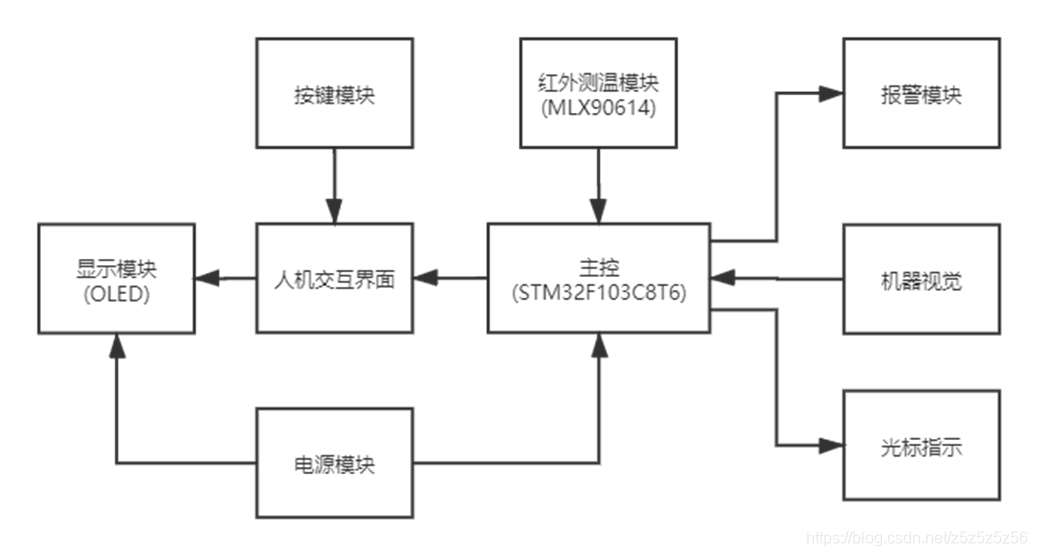
全体設計
ハードウェア選定
機械ビジョンモジュールにはOpenMVを使用しました。これは一方面は準備過程でOpenMVの機能が十分だと思っていたことと、もう一方面は当時K210を注文して学習を開始しても到着までに3日かかってしまうため、デバッグの時間がないリスクが大きすぎるからです。 그래서OpenMVを使用することにしました。
OpenMV H7 Plus
幸いにも最上位モデルのOpenMV H7 Plusを購入し、問題要求の全タスクを無事に完了しました。
温度測定にはMLX90614を使用し,某宝のモジュールでI2Cを読んで温度を読み取りました。最後に省一等奖をもらえずに省二等奖拿了となったのもこのモジュールのせいです。テスト現場で問題が発生し,血の教訓!常にPlan Bを準備しておきましょう!!
メインコントローラーにはSTM32C8T6を使用しました。これは赛前準備で既に使用していたためです。他のコントローラーでも可能です。
その他のハードウェアには,OLED温度しきい値表示,按鍵,有源ブザー,激光ポイントなどが含まれます。もう説明は不要でしょう。
最終的な回路基板設計,デバイスの配置は以下の通りです:

PCBレイアウト
ソフトウェアフロー
STM32とOpenMVはシリアル通信を行います。各モードに対応する文字を定義し,電源を入れるとOpenMVはループ内で文字を待ち受けます。文字を受信すると対応するモード機能を実行し,結果を返します。詳細はソフトウェアフローチャートを参照してください:
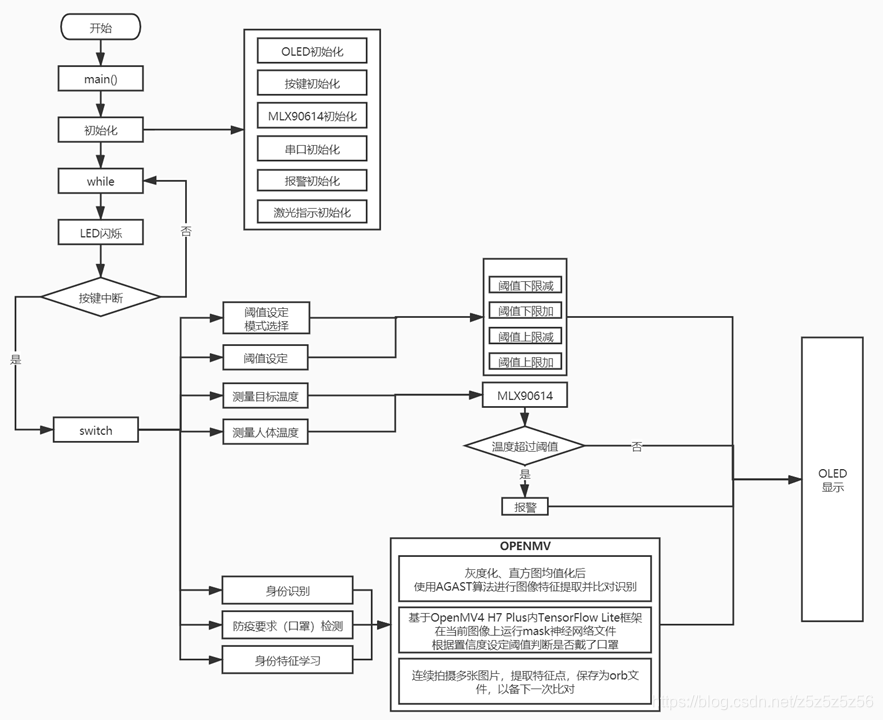
ソフトウェアフローチャート
ビジョンアルゴリズム
私は主にOpenMVのビジョン部分のコードを担当していたので,ここではPythonコード作成の経験について詳しく説明します。
学習段階で主に参考にした資料はSingTownの2つの関数ライブラリリンクです:
異なる顔の識別(身份認識)
問題を拿到后的第一反応是中国語入門教程で見たLBPで異なる顔を識別する応用でした。所以第一天按照手册的思路拍照测试しましたが,实际の効果はよくありませんでした。光と背景に大きく影響され,顔をカメラいっぱいに埋めなければならず,とても不便でした。
その後,特徵点アルゴリズムを発見し,計算時間が大きく向上しました。しかしまだ一个问题是:如果背景拍摄到的範囲が大きすぎると,从背景提取很多无用の特徵点になってしまい,一定の距離を保って顔を画面いっぱいに埋めなければならないのは本当に馬鹿馬lusしいです。
私の方法は:まず顔認識を一層追加し,顔の部分を局部的に拡大して切り取り,それから特徵点を抽出し特徵点比較を行います。この方法を使えば,被認識者に大きな要求がなくなり,K210のような機能を実装できます~
上記の思路についてのコードは以下の通りです:
#特徵点を描画
def draw_keypoints(img, kpts):
if kpts:
print(kpts)
img.draw_keypoints(kpts)
img = sensor.snapshot()
time.sleep(1000)
def find_max(pmax, a, s):
global face_num
if a>pmax:
pmax=a
face_num=s
return pmax
def Distinguish_faces():
global NUM_SUBJECTS
global NUM_SUBJECTS_IMGS
pyb.LED(3).on()
#センサーをリセット
sensor.reset()
sensor.set_contrast(3)
sensor.set_gainceiling(16)
sensor.set_framesize(sensor.VGA)
sensor.set_windowing((240, 240))
sensor.set_pixformat(sensor.GRAYSCALE)
sensor.set_auto_gain(True, gain_db_ceiling = 20.0)
sensor.skip_frames(time = 500)
pmax=0#検出点とサンプル点のマッチング度,保存が大きいほど近い,最小で初期化
loop_flag=1#ループ検出フラグ,顔を検出して識別したら退出
type_flag=0#kpts1クラス正解フラグ
while(loop_flag):
#histeqを追加,子適応ヒストグラム均衡化,顔が画面いっぱいの时可以提高一点点認識精度
#画像中の顔を検出
#gamma_corrは画像の色補正用,数値が高いほど画像が明るくなる
faces = sensor.snapshot().gamma_corr(contrast=1.5).find_features(image.HaarCascade("frontalface"))
lcd.display(sensor.snapshot())
if faces:
#画像中の最大顔を取得
largest_face = max(faces, key = lambda f: f[3] * f[3])
img=sensor.get_fb().crop(roi=largest_face)#顔を切り取り
kpts1=img.find_keypoints(max_keypoints=90, threshold=0, scale_factor=1.3)
if(type(kpts1).__name__=='kp_desc'):#kpts1的类型確保找到特徵点
type_flag=1
else:
print("kpts1 type wrong")
type_flag=0
else:
print("find no face")
#画像に顔があり,顔の部分から特徵点が見つかった場合のみ特徵点比較判断
if type_flag:
loop_flag=0
lcd.display(img)
draw_keypoints(img, kpts1)
num=0
#特徵点比較
kpts2=None
feature_values=[0]
for s in range(1, NUM_SUBJECTS+1):
match_count = int(0)
angle_count=0
for i in range(2, NUM_SUBJECTS_IMGS+1):
kpts2=image.load_descriptor("/keypoints/s%s/%s.orb"%(s,i))
match_count+=image.match_descriptor(kpts1, kpts2).count()
print("Average match_count for subject %d: %d"%(s, match_count))
pmax = find_max(pmax, match_count, s)
feature_values.append(match_count)
#平均値を計算
feature_sum=0
for feature_value in feature_values:
print("feature_value is %d" % feature_value)
n=len(feature_values)-1
feature_sum+=feature_value
average=feature_sum/n
print("average is %d" % average)
#分散を計算
pow_sum=0
for feature_value in feature_values:
if feature_value==0:
feature_value=average
print("此项分散は%d" % math.pow(feature_value-average,2))
pow_sum+=math.pow(feature_value-average,2)
variance=pow_sum/n
print("variance is %d" % variance)
#分散で判断,3人の結果が違えば分散は大きく,结果は信頼性が高い
if variance<1500:
uart.write(str(0))
print("unknown person !")
else:
uart.write(str(face_num))
print("The most similar person is:%d"%face_num)
lcd.clear()
pyb.LED(3).off()もちろんコードには还有很多其他细节。例えば最後に分散計算を追加しましたが,这是为了使得识别陌生人脸更准确。つまり,撮影された特徵点とメモリに保存された3人の特徵点との比較結果がほぼ同じで,分散が小さい場合,それは3人のうちの一人ではなく,见知らぬ人である可能性が高いです。この分散閾値は実践から得出されたもので,光によって调整が必要な場合があります。
以下にまとめます(短期習得版,系统的に学習理論は他の専門家を参照してください):
- LBP(ローカルバイナリパターン): 一定数量のテンプレートpgm画像データを収集。人顔認識時に,読み取った画像とテンプレートデータベースを類似度比較し,もっとも高い類似度のテンプレートを選択し,被テスト者情報を確定。
- 特徵点AGASTアルゴリズム: マルチスケール高速コーナー特徵抽出アルゴリズム。前もって目標特徴orbファイルを保存。人顔認識時に,目标の特徵点を抽出し特徵点ライブラりとマッチングして結果を出し,分散計算を経て信頼度を判断して結果を得出。
マスク認識
2つのモデルから生じる2つの異なる方法:
- 方法1: Haar演算子を使用し,XMLタイプファイルをcascadeフォーマットに変換してから認識。欠点は少量のサンプルでトレーニングしたマスクモデルの認識精度が低いこと。
- 方法2: 内蔵のTFLiteニューラルネットワークフレームワークを使用。现在OpenMV手册已经有了TFLite口罩认识模型,認識精度大幅向上。
現地学習
特徵点を使用するため,現地学習は撮影,特徵点抽出,ファイル保存を現地で行うだけです。私のロジックでは現地学習は難易度が上がらず,現地で20枚撮影すれば十分でした。
#特徵学習
def machine_learning():
sensor.reset()
sensor.set_contrast(3)
sensor.set_gainceiling(16)
sensor.set_framesize(sensor.VGA)
sensor.set_windowing((240, 240))
sensor.set_pixformat(sensor.GRAYSCALE)
sensor.set_auto_gain(True, gain_db_ceiling = 20.0)
sensor.skip_frames(time = 2000)
global NUM_SUBJECTS_IMGS
global NUM_SUBJECTS
print("last NUM_SUBJECTS =%d" % NUM_SUBJECTS)
NUM_SUBJECTS=NUM_SUBJECTS+1
print("now NUM_SUBJECTS =%d" % NUM_SUBJECTS)
p_num=NUM_SUBJECTS_IMGS
s=NUM_SUBJECTS
kpts1 = None
while(p_num):
#赤ライト点灯
pyb.LED(1).on()
faces = sensor.snapshot().gamma_corr(contrast=1.5).find_features(image.HaarCascade("frontalface"))
lcd.display(sensor.snapshot())
lcd.clear()
if faces:
largest_face = max(faces, key = lambda f: f[3] * f[3])
img=sensor.get_fb().crop(roi=largest_face)
lcd.display(img)
kpts1 = img.find_keypoints(max_keypoints=90, threshold=0, scale_factor=1.3)
if (kpts1 == None):
print("Couldn't find any keypoints!")
else:
draw_keypoints(img, kpts1)
lcd.display(img)
image.save_descriptor(kpts1, "keypoints/s%s/%s.orb"%(s,p_num))
img.save("keypoints/s%s/%s.pgm"%(s,p_num))
p_num-=1
print(p_num)
pyb.LED(1).off()
pyb.LED(3).on()
sensor.skip_frames(time = 50)
pyb.LED(3).off()
uart.write(str(9))
else:
print("find no face")
pyb.LED(2).on()
sensor.skip_frames(time = 100)
pyb.LED(2).off()
sensor.skip_frames(time = 100)
pyb.LED(2).on()
sensor.skip_frames(time = 100)
pyb.LED(2).off()
lcd.clear()
uart.write(str("f"))その他の最適化アルゴリズム
OpenMVで良い結果を得るために真的很努力呢哈哈哈
- ヒストグラム均衝化:
.histeq(adaptive=True, clip_limit=3)ヒストグラム均衝化後,グレースケールヒストグラムはEntire取る範囲をカバーし,そして一部のグレースケール値の個数が際立つ之外,全体的なグレースケール分布は均一分布に近くなります。这样处理的画像 はより大きなグレーンダイナミックレンジと高いコントラストを持ち,画像の詳細がより豊かになります。 - 局部拡大後認識:
sensor.get_fb().crop(roi=largest_face)まずファームウェアライブラリ自带の顔Haarモデル进行识别人脸之后,切り取った顔部分に対して特徵点比較を行います。これにより精度が向上し計算量が減少します。 - 自動ゲイン:
sensor.snapshot().gamma_corr(contrast=1.5)ガンマ補正は画像の色とコントラストの修正に使用され,数値が高いほど画像が明るくなります
总的来说那两天是把Micropython函数库翻了一遍,能试的都一个个试过去了这几つの関数は結果に確かに助けになった
まとめ
最終的に福建省二等奖を獲得しました。テスト時に90614モジュールが問題を起こし,温度測定が失敗した反而他の部分(ビジョン部分)は満点でした。省一等奖を取れなかったのはPlan Bを準備教训として受け止めましょう。
OpenMV部分のコードについては,主な内容は上記に全て記載されています。マスク認識はリンク先の公式を参照してください。以上の要点を書いたので,能力のある学生は再現できるはずです。
コメント欄で学習や議論,質問の解決や経験の共有をしましょう!ハードウェアとソフトウェアエンジニアリングコードは提供しません!!